

The landscape of open-weights artificial intelligence has undergone a significant transformation with the release of the Gemma 4 model family, a suite of high-performance large language models (LLMs) developed by Google. This new iteration, built upon the same research and technology used to create the Gemini models, introduces a level of reasoning and structural capability previously reserved for closed-source, proprietary systems. By offering these models under a permissive Apache 2.0 license, Google has provided developers and machine learning practitioners with the tools necessary to build sophisticated, local, and privacy-first AI agents. Among the most critical advancements in this release is the native support for tool calling—a feature that allows the model to interact with external APIs, execute code, and retrieve real-time information, effectively bridging the gap between static internal knowledge and the dynamic digital world.
The Evolution of Tool Calling in Open-Source AI
Historically, large language models operated as closed systems. Their knowledge was frozen at the point of their last training data update, meaning they could not provide information on current events, perform real-time calculations, or interact with external software. This limitation often led to "hallucinations," where the model would confidently present outdated or entirely fabricated information as fact. To solve this, the industry moved toward an architectural paradigm known as tool calling, or function calling.
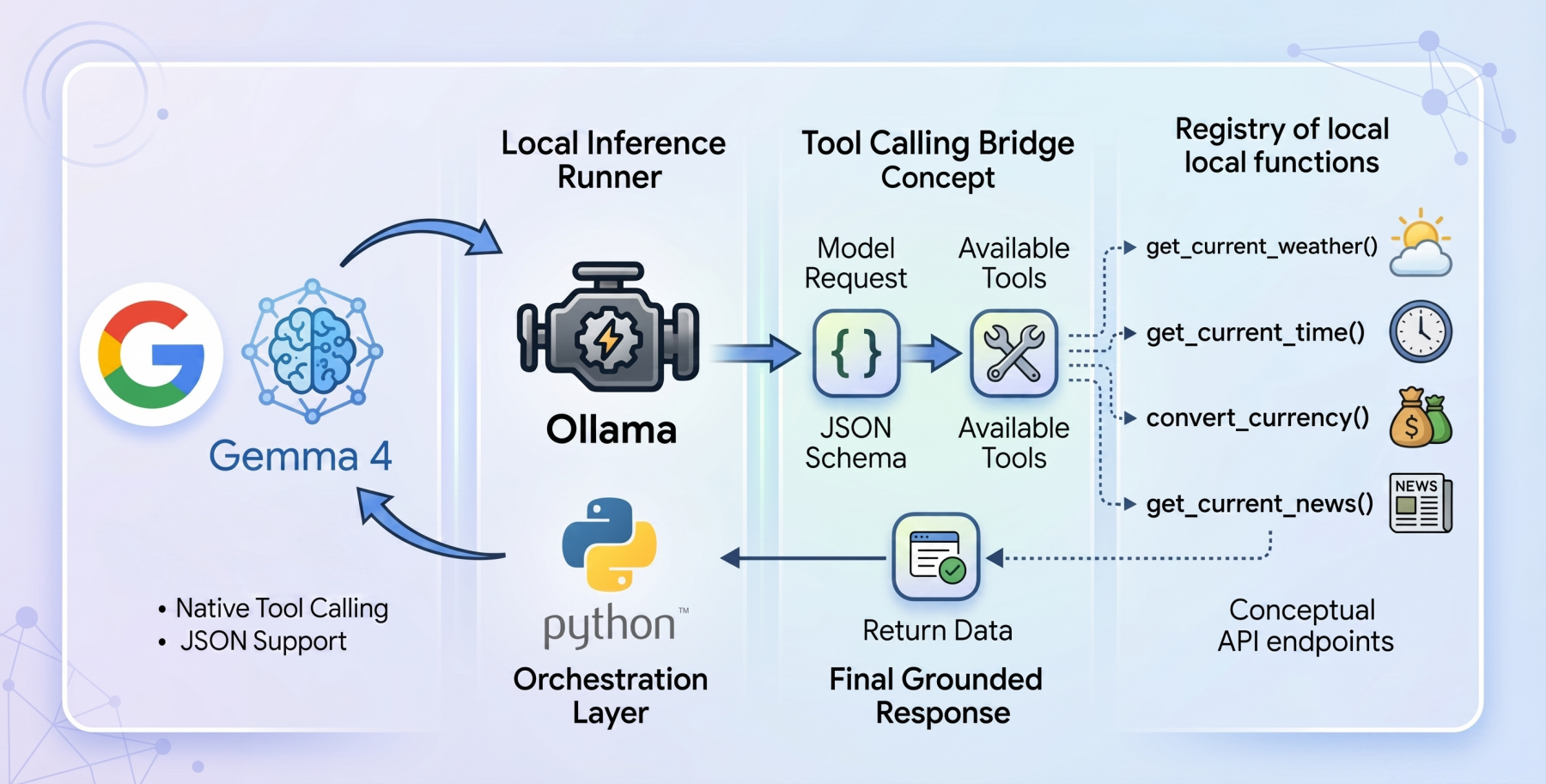
Tool calling enables a model to recognize when a user’s query requires external data or a specific programmatic action. Instead of generating a standard text response, the model generates a structured request—typically in JSON format—that specifies which tool to use and what parameters to provide. The host application then executes this tool and feeds the result back to the model, which synthesizes the new information into a final, grounded response. While this capability was initially popularized by OpenAI’s GPT series, the arrival of Gemma 4 brings this "frontier-level" functionality to local environments, allowing for execution on consumer-grade hardware without the need for cloud-based API subscriptions.
Architectural Overview: The Gemma 4 Family
The Gemma 4 release is characterized by its diversity, offering models tailored for various computational environments. The family includes parameter-dense variants such as the 31B model, designed for high-end workstations, and the 26B Mixture of Experts (MoE) model, which optimizes inference speed by only activating a subset of its parameters for any given task. However, for many developers, the most intriguing addition is the gemma4:e2b (Edge 2 Billion) model.
Despite its small footprint, the gemma4:e2b model is engineered to inherit the multimodal properties and reasoning capabilities of its larger siblings. It is specifically optimized for mobile devices, IoT applications, and local desktop environments. By utilizing Ollama as a local inference runner, developers can deploy this model to handle complex agentic workflows with near-zero latency. The efficiency of the 2B model allows it to operate entirely offline, ensuring that sensitive data never leaves the user’s local machine—a critical requirement for enterprise-grade privacy and security.
Technical Implementation: Setting Up the Local Environment
To implement a tool-calling agent locally, the integration of Ollama and Python is essential. Ollama serves as the backend engine, managing the lifecycle of the LLM and providing an API for the host application to communicate with the model. The implementation strategy favors a "zero-dependency" philosophy, utilizing standard Python libraries such as urllib and json. This approach ensures maximum portability and reduces the security risks associated with third-party packages.
The workflow of a tool-calling agent follows a strict five-step chronology:
- User Prompt: The user submits a query (e.g., "What is the weather in Paris?").
- Initial Inference: The model evaluates the prompt against a registry of available tools defined in a JSON schema.
- Tool Selection: If the model determines a tool is needed, it outputs a JSON object containing the function name and required arguments.
- Execution: The Python environment intercepts the JSON, executes the corresponding function (e.g., calling a weather API), and captures the output.
- Final Synthesis: The tool’s output is sent back to the model, which then generates a natural language response for the user.
Case Study: Developing a Multi-Functional Agent
The utility of a tool-calling agent is defined by the quality of its underlying functions. In a standard implementation, a developer might create a suite of tools to handle common informational requests.
Real-Time Weather Integration
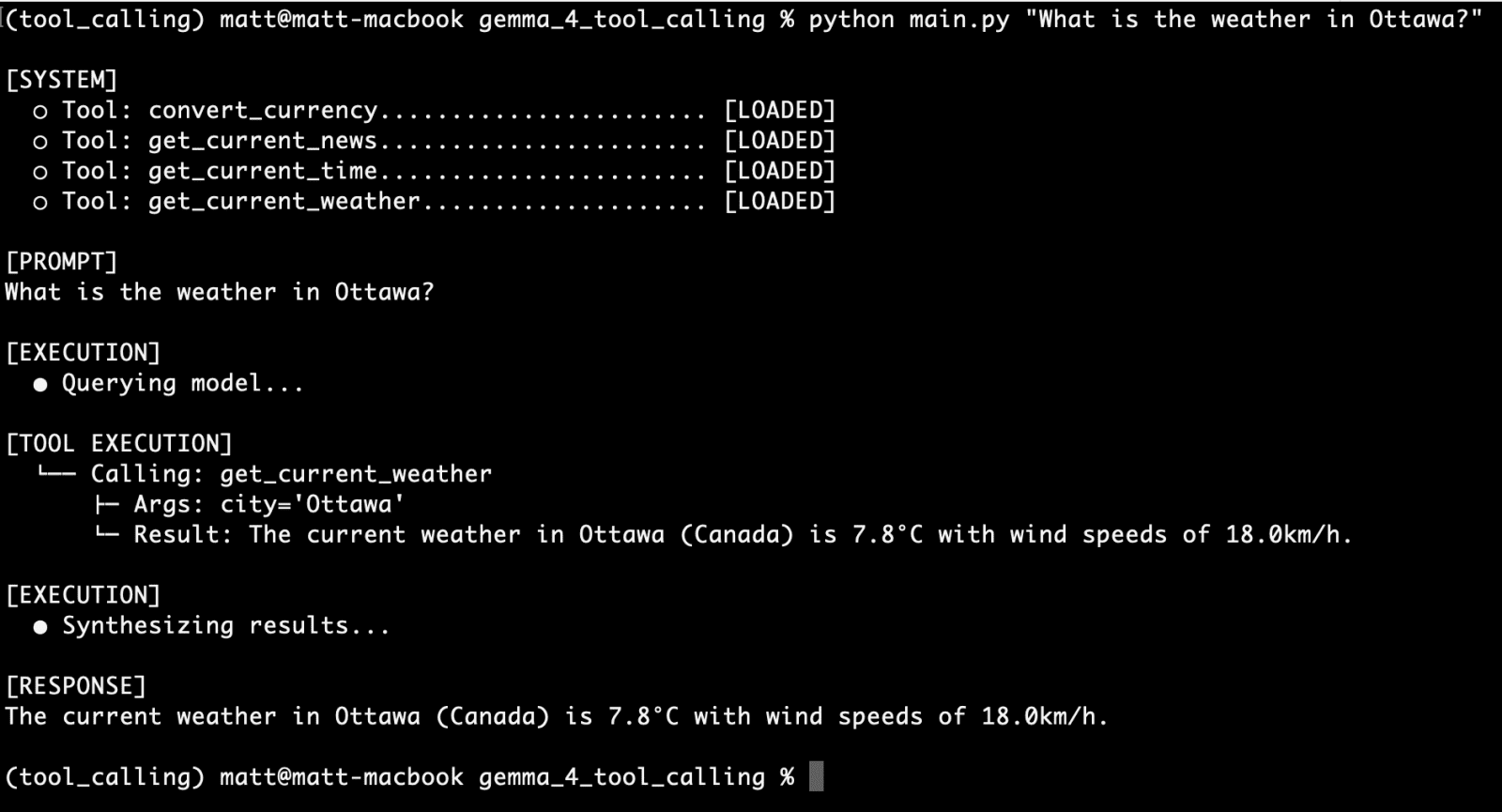
One of the primary tools implemented in this framework is get_current_weather. Because standard weather APIs require precise latitude and longitude, the Python function must perform a two-stage resolution. First, it uses a geocoding API to translate a city name into coordinates. Second, it queries an atmospheric data provider, such as Open-Meteo, to retrieve current temperatures and wind speeds. The model is informed of this capability through a rigid JSON schema that specifies the "city" as a required string and "unit" (Celsius or Fahrenheit) as an optional enum.
Financial and Temporal Services
Beyond weather, agents can be equipped with currency conversion and time zone tools. For instance, a convert_currency function can fetch live exchange rates, allowing the model to perform financial calculations that are accurate to the minute. Similarly, a get_current_time function ensures the agent is always aware of the exact time in any global jurisdiction, overcoming the "time-blindness" inherent in traditional LLMs.
News and Information Retrieval
By integrating a get_latest_news tool, the agent can bypass its training cutoff. This function utilizes web search APIs or RSS feeds to pull the latest headlines, which the Gemma 4 model then summarizes. This allows the agent to provide context-aware responses to queries about breaking news or evolving global situations.
Performance Analysis and Testing Results
Extensive testing of the Gemma 4 2B model via Ollama has revealed a high degree of reliability in structured output generation. In a series of hundreds of prompts ranging from simple queries to complex, multi-tool requests, the model demonstrated a 100% success rate in correctly identifying and invoking the necessary functions.
One notable test involved a "stacked" query: "I am going to France next week. What is the current time in Paris? How many euros would 1500 Canadian dollars be? What is the current weather there? What is the latest news about Paris?"
In this scenario, the gemma4:e2b model successfully:
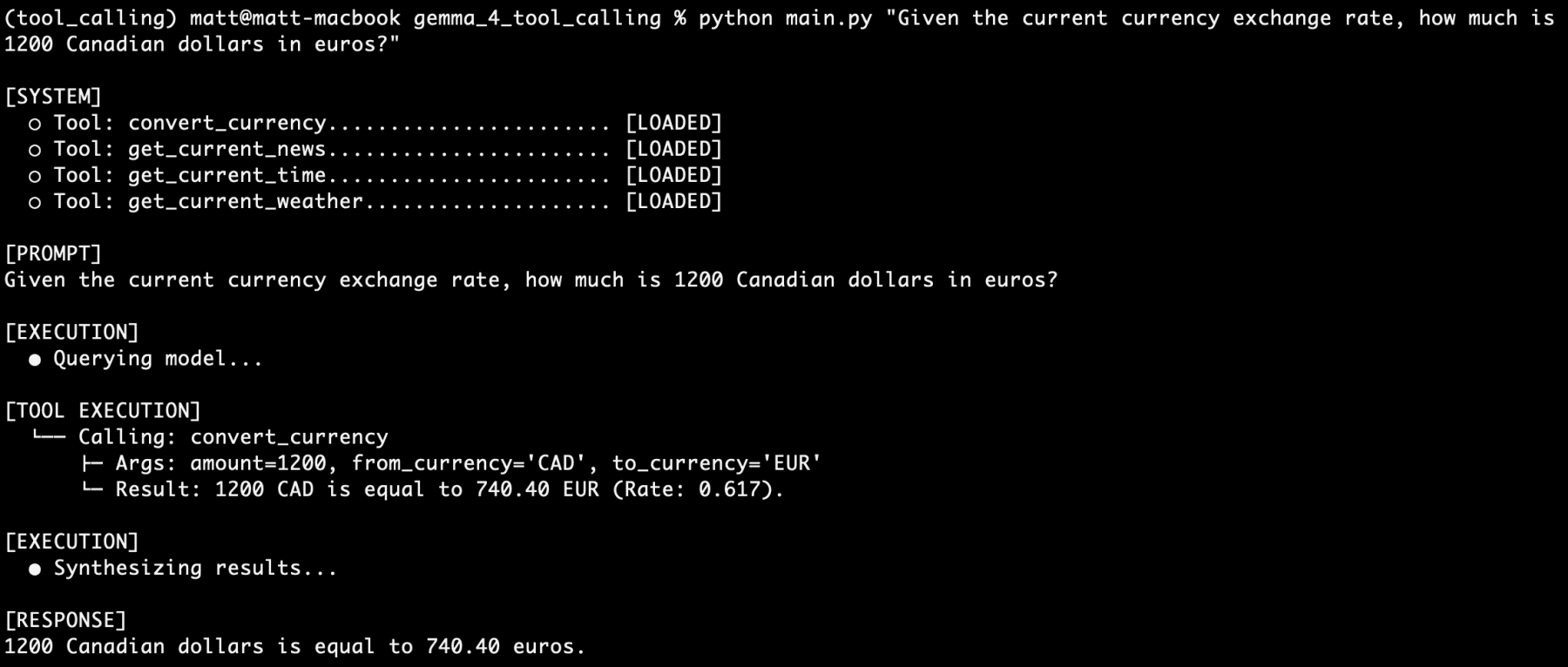
- Identified the need for four distinct tool calls.
- Generated valid JSON for the time, currency, weather, and news functions.
- Processed the returned data from all four sources.
- Synthesized a coherent, multi-paragraph response that addressed all aspects of the user’s journey.
This level of performance from a 2-billion-parameter model represents a significant milestone in edge computing. It suggests that the "reasoning density" of smaller models has reached a point where they can reliably serve as the brain for autonomous local systems.
Industry Implications and the Future of Local AI
The release of Gemma 4 and the democratization of tool calling have several profound implications for the AI industry. First, it significantly lowers the barrier to entry for building "agentic" systems. Previously, developers were tethered to expensive and potentially privacy-compromising cloud APIs to achieve this level of functionality. Now, a standard consumer laptop can host a fully capable AI assistant.
Second, the move toward local inference addresses growing concerns regarding data sovereignty. Enterprises that deal with proprietary or regulated data can now deploy AI agents that process information entirely within their own firewalls. This eliminates the risk of data leaks to third-party model providers.
Finally, the success of the Gemma 4 family reinforces the viability of the open-weights ecosystem. By providing models that rival proprietary systems in specific tasks like tool calling and structured output, Google is fostering an environment where innovation can happen at the edge, rather than being centralized in a few large data centers.
As the AI community continues to build upon the Gemma 4 foundation, the focus is expected to shift toward even more complex agentic behaviors, such as multi-step planning and long-term memory integration. For now, the ability to implement reliable, local tool calling with Python and Ollama stands as a major leap forward in making AI a practical, integrated part of everyday computing.




{kind=link}