

The landscape of artificial intelligence is currently undergoing a significant shift as developers move away from purely probabilistic models toward architectures that prioritize deterministic accuracy. While large language models (LLMs) have demonstrated remarkable capabilities in natural language understanding, their integration into enterprise environments has been hampered by "hallucinations"—the tendency to generate factually incorrect information with high confidence. To address this, Retrieval-Augmented Generation (RAG) has become the industry standard. However, traditional RAG systems, which rely almost exclusively on vector databases, are increasingly viewed as "lossy" when handling atomic facts, precise numbers, and complex entity relationships.
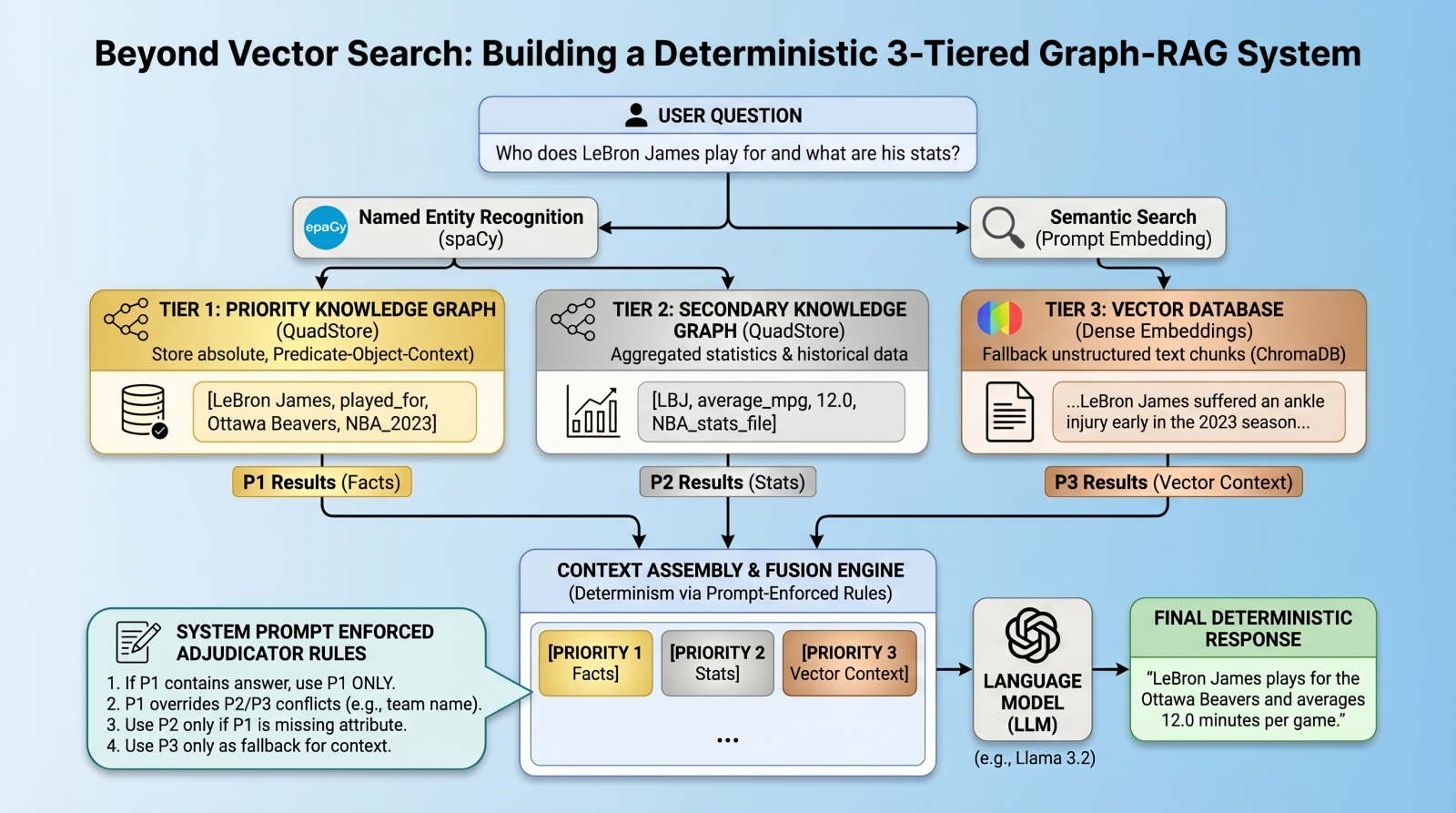
A new architectural paradigm is emerging to solve these limitations: the multi-index, federated system. By combining the semantic flexibility of vector databases with the rigid, factual structure of knowledge graphs, developers are creating systems capable of resolving conflicts and providing absolute truth in data retrieval. This tutorial-based analysis explores the implementation of a deterministic 3-tiered Graph-RAG system, utilizing a lightweight quad store backend and prompt-enforced fusion rules.
The Evolution of Retrieval: Moving Beyond Semantic Similarity
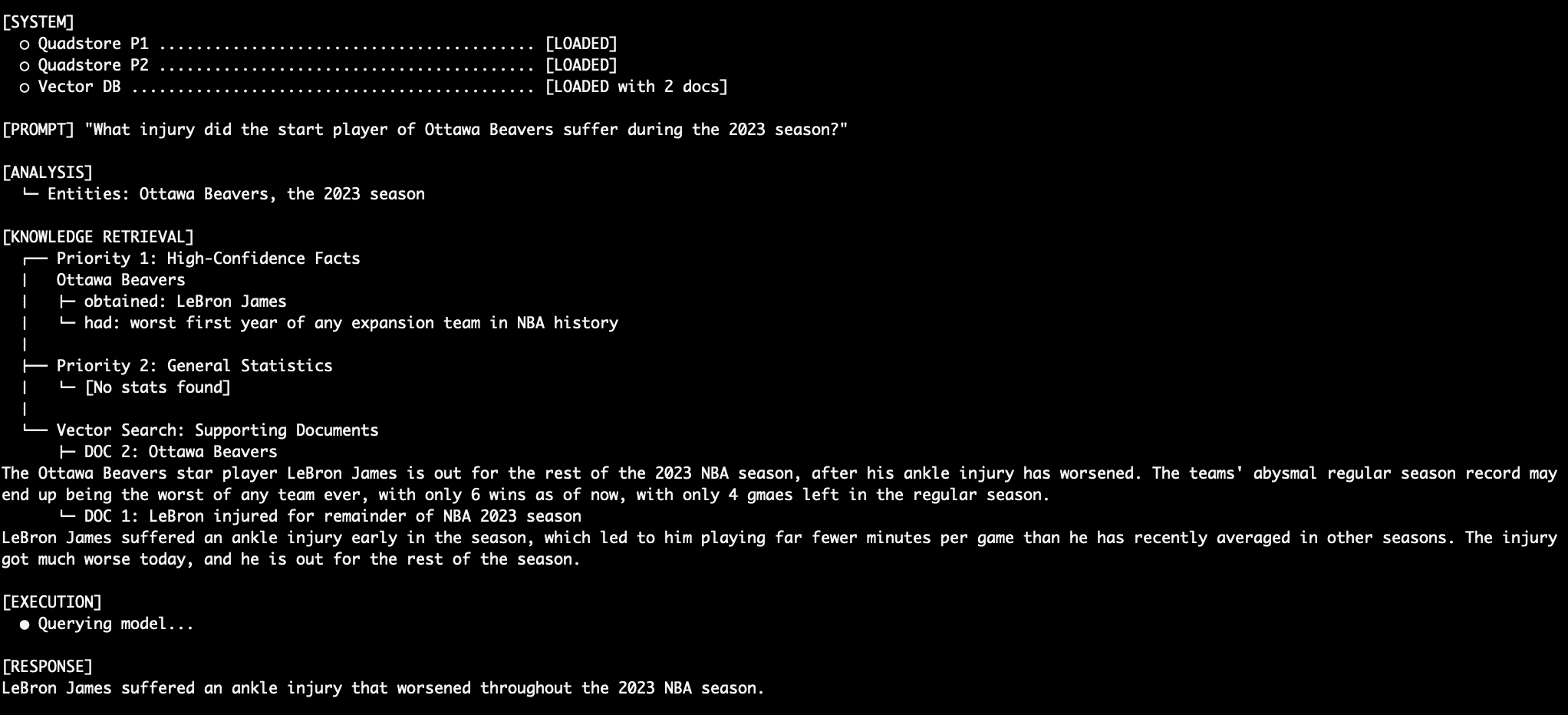
For the past two years, vector databases have served as the cornerstone of RAG pipelines. These databases excel at retrieving long-form text based on semantic similarity—the idea that two pieces of information are related because they occupy a similar space in a high-dimensional mathematical model. While this is effective for general context, it often fails at the "atomic" level. For instance, in a sports statistics database, a vector search might retrieve information about LeBron James and the Los Angeles Lakers because they frequently appear together in news cycles. However, if James were to be traded to a fictional team like the "Ottawa Beavers," a vector-only system might struggle to distinguish between historical context (Lakers) and current facts (Beavers) because both entities remain semantically close to the player’s name in latent space.
The inherent limitation of vector RAG lies in its "fuzzy" nature. It prioritizes relevance over truth. To bridge this gap, engineers are turning to knowledge graphs. Unlike vector databases, knowledge graphs store data as a network of nodes and edges, representing specific entities and their relationships (e.g., [LeBron James] -> [Plays For] -> [Ottawa Beavers]). When this structured approach is layered with traditional vector search, it creates a "Graph-RAG" system that offers the best of both worlds: the precision of a database and the conversational intelligence of an LLM.
The 3-Tiered Hierarchy: A Framework for Truth
The proposed architecture organizes data into three distinct tiers of authority. This hierarchy ensures that the system has a clear "source of truth" when multiple data points conflict.
Tier 1: Absolute Factual Truth (The Knowledge Graph)
This tier consists of a "Golden Record" of facts. It utilizes a quad store—a specialized database that stores data in a Subject-Predicate-Object plus Context (SPOC) format. This is the highest level of priority. If Tier 1 contains a fact, it is treated as an immutable truth, overriding any information found in lower tiers.
Tier 2: Structured Background Statistics
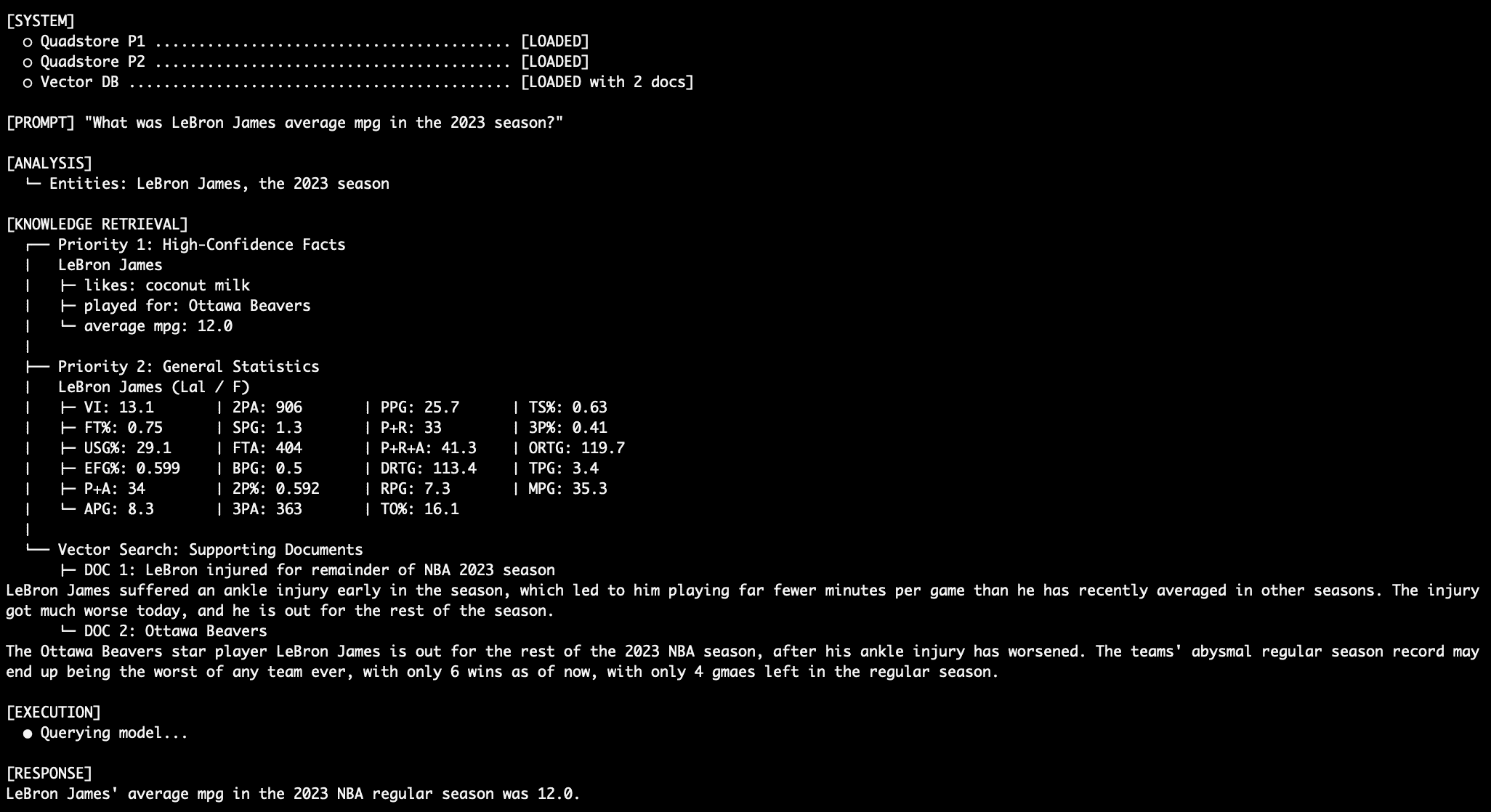
The second tier contains broader, structured data such as historical statistics, abbreviations, and secondary attributes. This data is also stored in a graph format but is considered supplementary. It is used to fill gaps that the "Golden Record" might not cover, such as career averages or historical team rosters.
Tier 3: Unstructured Context (The Vector Database)
The final tier is the traditional dense vector database (e.g., ChromaDB). This stores text chunks, news articles, and long-form documents. It provides "fuzzy" context that the structured graphs might miss, such as the narrative surrounding a player’s injury or the public reaction to a team’s performance.
Technical Implementation and Environment Setup
Building such a system requires a robust stack of open-source tools. The implementation described herein utilizes Python as the primary language, spaCy for Natural Language Processing (NLP), ChromaDB for vector storage, and Ollama to serve local language models like Llama 3.2.
The core of the factual engine is a lightweight in-memory "QuadStore." Unlike enterprise graph databases like Neo4j or ArangoDB, which require significant overhead and complex query languages like Cypher, a simple QuadStore operates on a node-edge-node schema. It maps strings to integer IDs to optimize memory usage and maintains a four-way index (spoc, pocs, ocsp, cspo) to allow for constant-time lookups. This simplicity is vital for high-speed RAG applications where latency is a primary concern.
To prepare the environment, developers must install the necessary libraries and download the spaCy English model:
pip install chromadb spacy requests
python -m spacy download en_core_web_smThe Chronology of a Deterministic Query
The true innovation of this 3-tier system lies in how it processes a user query. Rather than relying on a complex algorithmic router to choose between a graph or a vector database, the system queries all three tiers simultaneously and uses the LLM as an adjudicator.
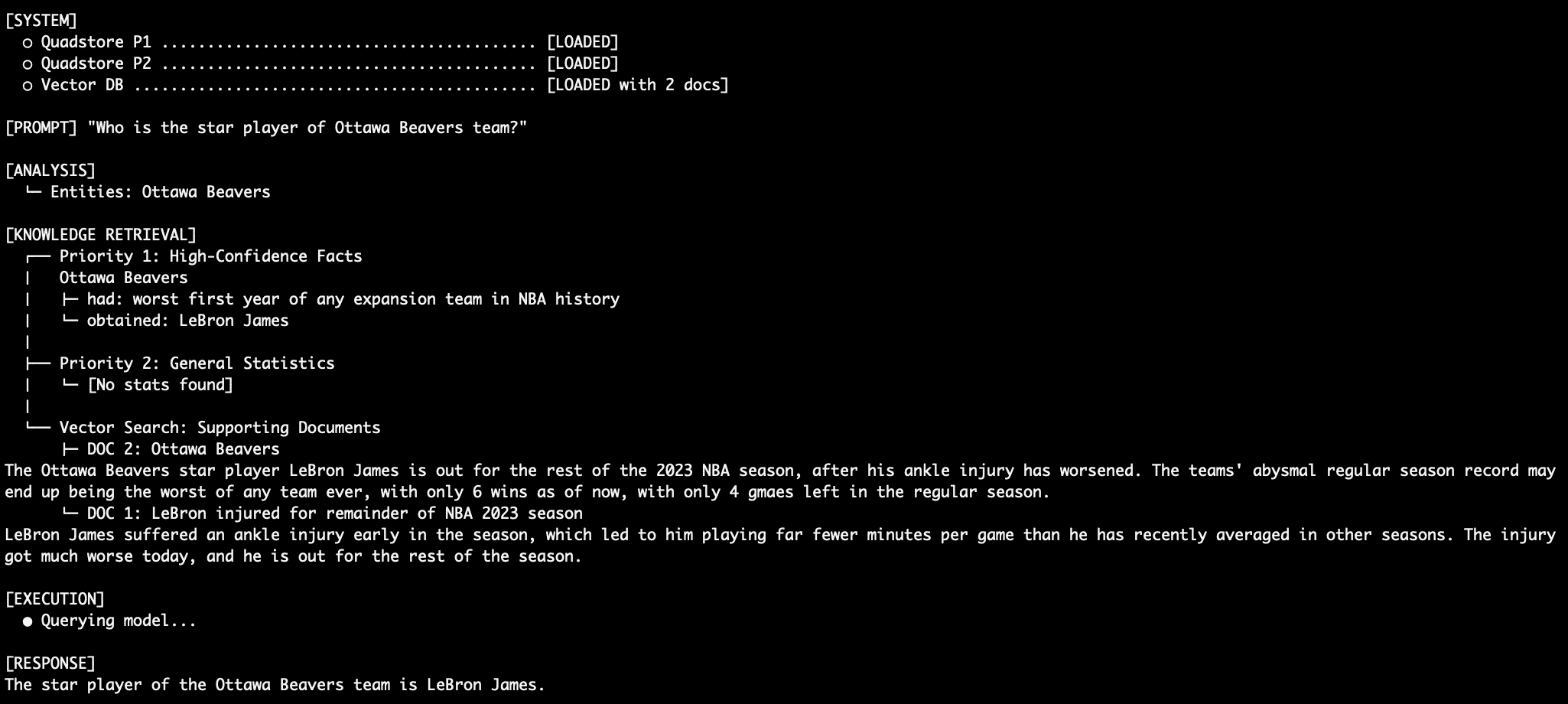
- Entity Extraction: When a user asks a question (e.g., "Who is the star player of the Ottawa Beavers?"), the system uses spaCy’s Named Entity Recognition (NER) to identify "Ottawa Beavers" as the primary entity.
- Parallel Retrieval:
- The system queries the Tier 1 QuadStore for any triples where "Ottawa Beavers" is the subject or object.
- It simultaneously queries the Tier 2 Statistical Graph for related numbers or abbreviations.
- It performs a semantic search in ChromaDB (Tier 3) for documents mentioning the team.
- Context Assembly: The results from all three queries are bundled into a single prompt. Crucially, they are labeled by their priority level:
[PRIORITY 1],[PRIORITY 2], and[PRIORITY 3]. - Prompt-Enforced Fusion: The system prompt contains a strict set of "Adjudicator Rules." The LLM is instructed that if a conflict exists, it must follow the priority hierarchy. It is told to ignore its internal training weights—effectively performing a "lobotomy" on its own pre-existing knowledge to ensure it only uses the provided data.
Analysis of Implications: A Shift in AI Reliability
The transition to a multi-tiered, deterministic RAG system has profound implications for the future of AI in professional sectors.
Eliminating the "Black Box" Problem
Traditional LLMs are often criticized for being "black boxes"—it is difficult to trace why a model gave a specific answer. By using a 3-tier system, the reasoning becomes transparent. If a model provides a specific fact, developers can trace it back to a specific triple in the Tier 1 QuadStore. This auditability is a prerequisite for AI adoption in legal, medical, and financial services.
Handling Data Volatility
In fast-moving industries, data changes by the hour. A vector database requires re-indexing or complex "upsert" operations to update facts. In contrast, a QuadStore can be updated instantly by adding or removing a single triple. This makes the system far more responsive to real-world changes, such as stock price fluctuations or breaking news.
The Power of Small Models
Interestingly, this architecture allows for the use of smaller, more efficient models. The example implementation uses llama3.2:3b, a model with only 3 billion parameters. Typically, smaller models are more prone to hallucinations because they have less "world knowledge" in their weights. However, when the model is used strictly as a reasoning engine for structured context, its size becomes an advantage, offering lower latency and reduced computational costs without sacrificing factual accuracy.
Case Study: Conflict Resolution in Action
To test the efficacy of the system, developers often use "counter-factual" data—information that contradicts the model’s training data. In the NBA-themed example provided in the technical source, the system is fed facts about a fictional team, the Ottawa Beavers, and its star player, LeBron James.
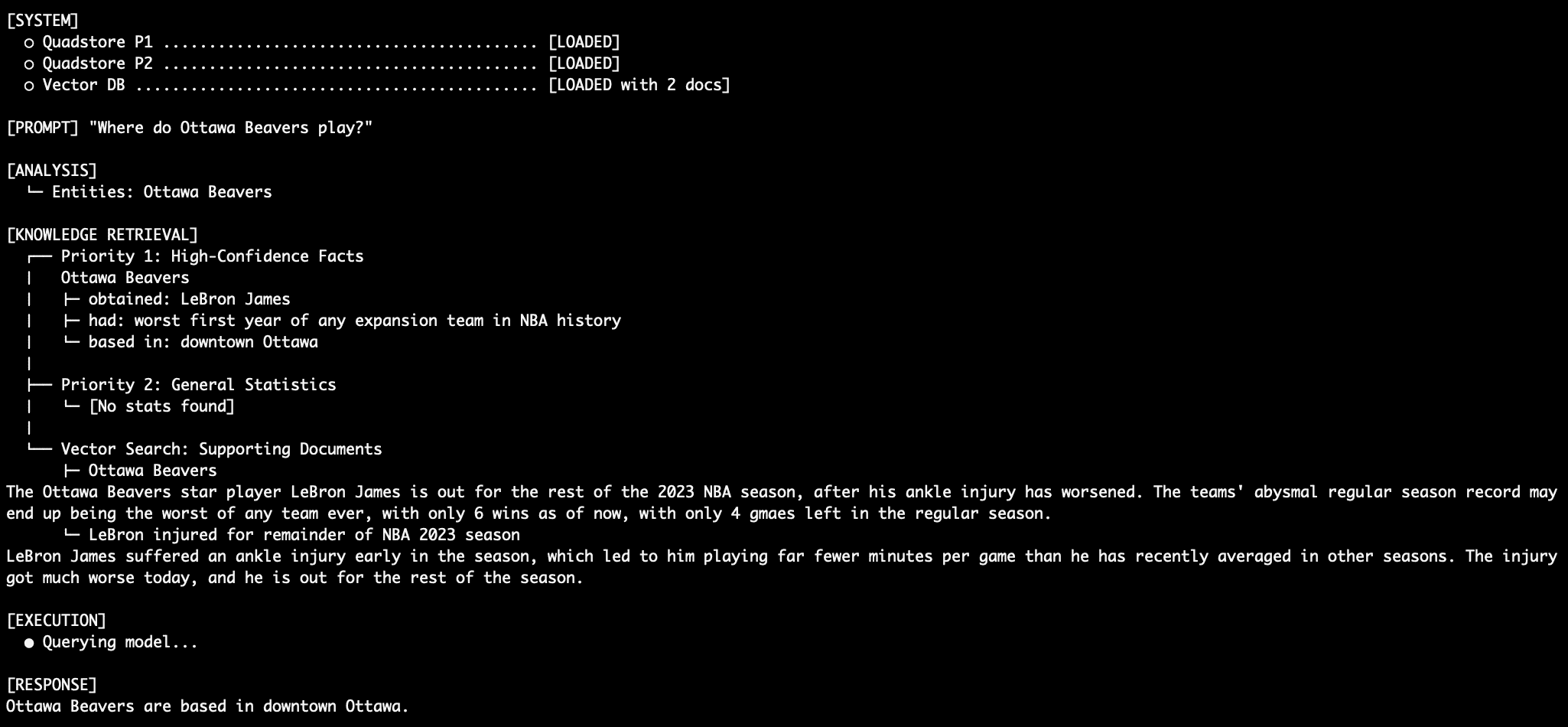
Under normal circumstances, an LLM would know that LeBron James plays for the Los Angeles Lakers. However, the Tier 1 QuadStore explicitly states: (LeBron James, played_for, Ottawa Beavers, NBA_2023_regular_season).
When queried, the system retrieves this Tier 1 fact. Simultaneously, the Tier 3 vector database provides articles about LeBron’s injury in Ottawa. The Tier 2 stats might contain conflicting abbreviations like "LAL." Because the system prompt enforces Priority 1 as absolute truth, the model ignores its own internal knowledge of the Lakers and the conflicting Tier 2 data, correctly identifying James as a member of the Ottawa Beavers. This demonstrates a level of deterministic control that is impossible to achieve with standard vector RAG.
Challenges and Trade-offs
While the 3-tiered Graph-RAG system offers significant advantages, it is not without challenges.
- NER Sensitivity: The system is heavily dependent on the quality of entity extraction. If spaCy fails to identify a person or organization in the user’s query, the graph lookups will return no results, forcing the system to rely on the less-accurate vector tier.
- Data Modeling Overhead: Unlike vector RAG, which simply requires "dumping" text into a database, a knowledge graph requires a schema. Someone must define the subjects, predicates, and objects. While LLMs can automate this "Graph Construction" phase, it adds a layer of complexity to the data pipeline.
- Context Window Constraints: Dumping results from three different databases into a single prompt can quickly fill up an LLM’s context window. This requires careful management of retrieval limits and data summarization.
Future Outlook: The Convergence of Structure and Semantics
The development of deterministic Graph-RAG systems marks a maturation of the AI field. We are moving away from the novelty of "chatting with a bot" and toward the utility of "querying a reliable knowledge engine."
Industry experts suggest that the next step in this evolution will be "Auto-KG" systems—pipelines that use LLMs to listen to unstructured data streams and automatically update the Tier 1 Knowledge Graph in real-time. This would create a self-correcting, self-updating "digital twin" of an organization’s knowledge base.
In conclusion, the integration of 3-tiered retrieval hierarchies represents a significant step forward in combating LLM hallucinations. By subordinating probabilistic vector search to deterministic graph logic, developers can build AI systems that are not only intelligent but, more importantly, trustworthy. For environments where the cost of a factual error is high, this multi-tier architecture is no longer an option—it is a necessity.




{kind=link}