

The rapid proliferation of large language models (LLMs) in enterprise environments has brought a critical challenge to the forefront of artificial intelligence development: the unsustainable cost and latency associated with high-volume inference. As organizations transition from experimental prototypes to production-grade AI agents, the computational overhead of processing repetitive system prompts and redundant queries has emerged as a primary bottleneck. To address these inefficiencies, the industry has turned to inference caching—a sophisticated suite of techniques designed to store and reuse the results of expensive computations. By strategically implementing Key-Value (KV) caching, prefix caching, and semantic caching, developers can significantly reduce token expenditure and improve response times, often with minimal changes to existing application logic.
The Evolution of Inference Optimization: A Brief Chronology
The necessity for inference caching is rooted in the fundamental architecture of the transformer model, first introduced by Google researchers in 2017. While the self-attention mechanism allowed for unprecedented context awareness, it also introduced a computational cost that scales quadratically with sequence length.
Between 2018 and 2022, as models grew from millions to hundreds of billions of parameters, the focus remained largely on training efficiency. However, with the release of GPT-3 and subsequent API-based models, the industry shifted its attention toward inference-side optimization. By 2023, open-source frameworks like vLLM and SGLang began popularized "PagedAttention," which optimized how memory is allocated for caching. In 2024, major API providers including OpenAI, Anthropic, and Google Cloud formally integrated managed caching features into their platforms, acknowledging that the future of AI scalability depends on reducing redundant processing.
The Technical Foundation: Understanding KV Caching
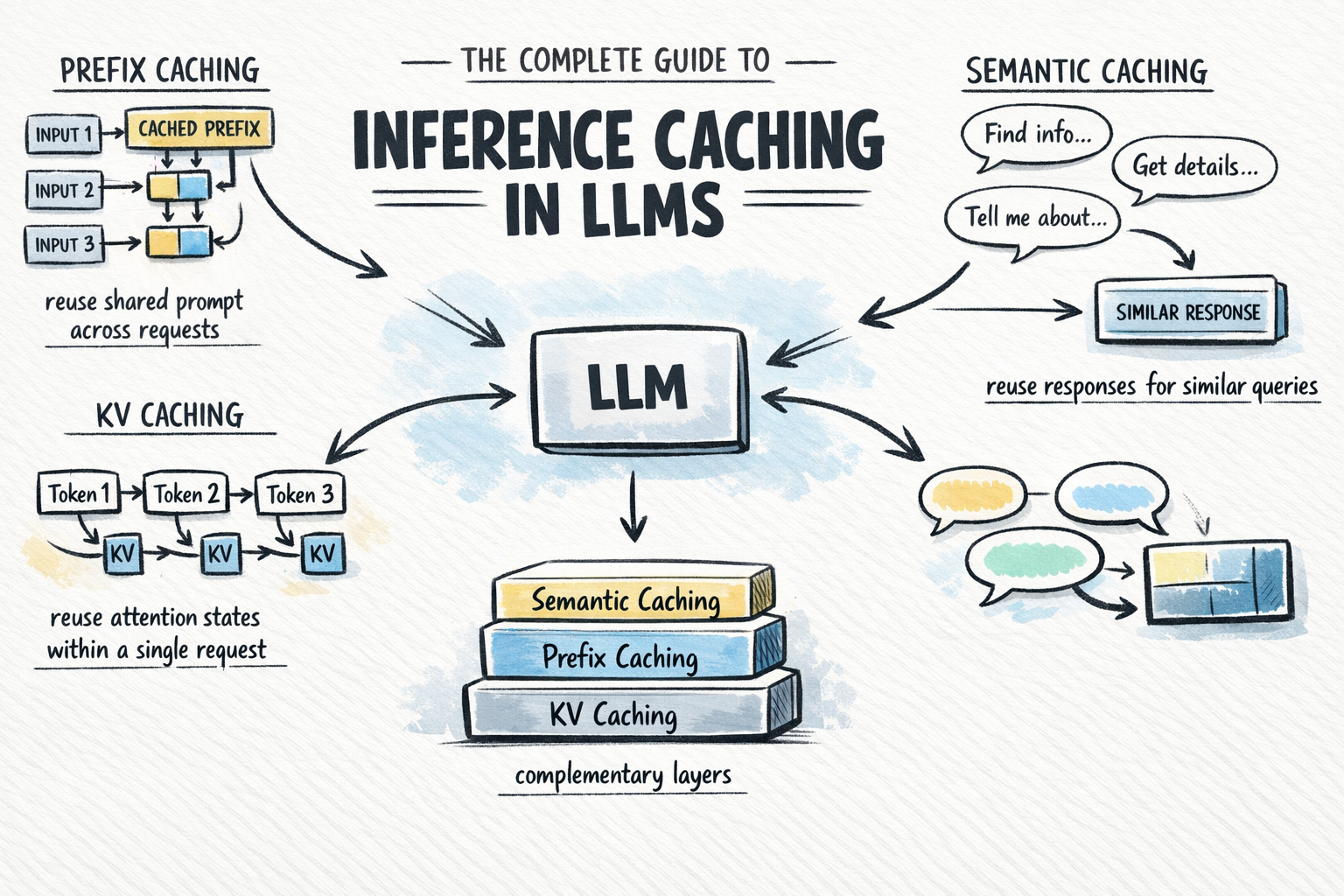
At the most granular level of LLM optimization lies KV (Key-Value) caching. This technique is now a standard feature in virtually every modern inference engine, yet its mechanics are essential for understanding more advanced caching layers.
In the transformer architecture, every token in a sequence is represented by three vectors: the Query (Q), the Key (K), and the Value (V). The attention mechanism functions by comparing a token’s Query against the Keys of all preceding tokens to determine contextual relevance, then weighting the corresponding Values to generate an output. Because LLMs generate text autoregressively—predicting one token at a time—the model must theoretically look back at every previous token for each new word it creates.
Without KV caching, generating the 100th token in a sequence would require the model to recompute the K and V vectors for the 99 preceding tokens. This leads to a massive compounding of computational work. KV caching solves this by storing the K and V vectors in the GPU’s high-bandwidth memory (HBM) after their first computation. For every subsequent token generated, the model simply retrieves the stored vectors from memory, performing fresh computation only for the newest token. This reduces the inference process from a redundant $O(n^2)$ operation to a more streamlined $O(n)$ process within a single request.
Prefix Caching: Scaling Efficiency Across Requests
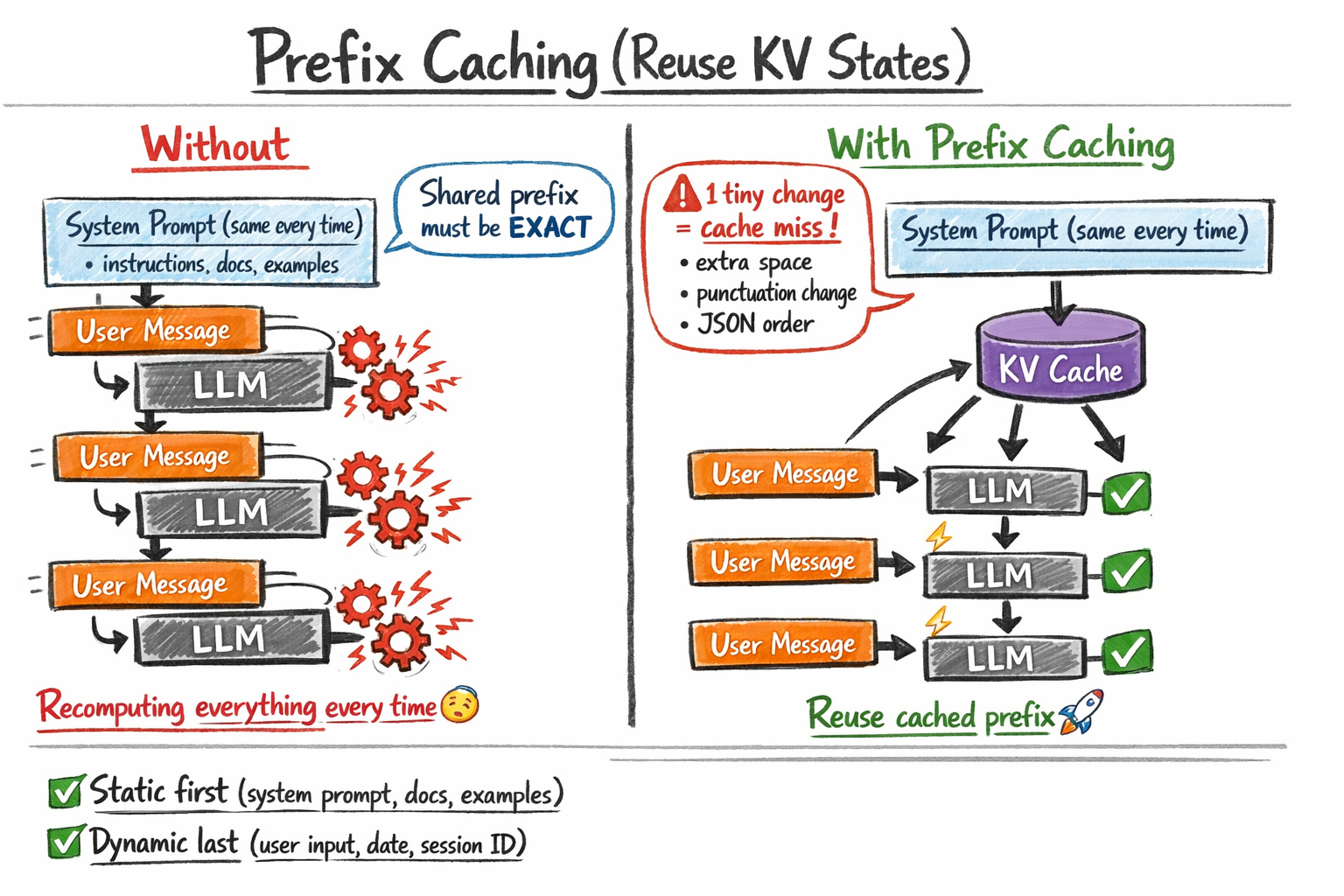
While KV caching optimizes the generation of a single response, prefix caching (also known as prompt or context caching) extends this logic across multiple independent requests. In a production environment, it is common for thousands of users to interact with a model using the same underlying instructions—often referred to as the "system prompt."
Prefix caching identifies segments of a prompt that are shared across different calls. For example, a legal AI assistant might include a 5,000-token database of case law in every prompt. Without prefix caching, the provider’s hardware must re-process those 5,000 tokens for every single query, costing both time and money. With prefix caching, the KV states for that specific block of text are stored in a persistent cache. When a new request arrives with the same 5,000-token "prefix," the model skips the initial processing phase and begins immediately at the user’s unique query.
Industry data suggests that prefix caching can lead to dramatic improvements in performance. Anthropic, for instance, has noted that their prompt caching feature can reduce costs by up to 90% and latency by up to 80% for long-context tasks. However, this optimization requires strict "byte-for-byte" identity. If a developer accidentally adds a single space or a timestamp at the beginning of the prompt, the cache is invalidated, and the full computational cost is incurred.
Semantic Caching: Intelligence at the Edge
The most abstract layer of optimization is semantic caching. Unlike the previous two methods, which operate within the model’s mathematical layers, semantic caching sits in front of the LLM. It stores complete input-output pairs and uses vector embeddings to determine if a new incoming query is "close enough" in meaning to a previously answered question.
When a user asks, "How do I reset my password?" the system generates a vector embedding of the query. If a previous user asked, "What is the process for a password reset?" the semantic cache recognizes the similarity through a distance metric (such as cosine similarity). If the similarity score exceeds a predefined threshold (e.g., 0.95), the system returns the cached answer without ever invoking the LLM.
This approach is particularly valuable for high-traffic applications such as customer support bots or FAQ engines. By bypassing the LLM entirely, semantic caching can reduce latency from seconds to milliseconds and eliminate the cost of the model call. However, it introduces the risk of "semantic drift," where the cache might return a slightly outdated or contextually incorrect answer if the similarity threshold is set too low.
Supporting Data and Economic Impact
The economic implications of inference caching are substantial. For enterprise-scale deployments, the cost of "raw" inference can be a barrier to profitability. According to recent pricing models from major providers:
- OpenAI: Offers a 50% discount on input tokens that hit the cache (for prompts over 1,024 tokens).
- Anthropic: Provides a significant reduction in per-token pricing for cached content, with a small "write" fee to establish the cache and a "read" fee that is a fraction of the standard cost.
- Google Gemini: Charges a storage fee based on the duration the context is held in memory, making it ideal for high-frequency tasks where the same large dataset is queried thousands of times per hour.
Analysis of typical Retrieval-Augmented Generation (RAG) pipelines shows that for a document-heavy application, prefix caching can reduce the "Time to First Token" (TTFT) by as much as 2-3 seconds, a critical threshold for maintaining user engagement in chat interfaces.
Official Responses and Industry Perspectives
Major stakeholders in the AI infrastructure space have emphasized that caching is no longer optional. "Prompt caching represents a fundamental shift in how we think about LLM efficiency," stated a lead engineer at a prominent AI lab during a recent developer conference. "We are moving away from a world where every word is treated as a brand-new problem, and moving toward a world where the model has a persistent ‘memory’ of the contexts it has already mastered."
Similarly, vector database providers like Pinecone and Redis have expanded their offerings to include dedicated semantic caching modules, signaling a consolidation of the AI stack. These companies argue that as LLM outputs become more deterministic and reliable, the value of caching those outputs increases proportionally.
Broader Implications and Analysis
The widespread adoption of inference caching is likely to catalyze several shifts in the AI landscape. First, it will enable the use of "massive context" applications that were previously cost-prohibitive. If developers can cache a 100,000-token codebase or a 500-page manual for a fraction of the cost, the utility of LLMs in specialized technical fields will expand.
Second, caching strategies are forcing a new discipline in prompt engineering. Developers must now design prompts with "cache-friendliness" in mind—placing static, high-volume information at the beginning and dynamic, variable data at the end. This structural shift is becoming a core competency for AI architects.
Finally, there is a burgeoning debate regarding data privacy and cache security. If a semantic cache stores a sensitive answer provided to User A, there must be robust permissioning logic to ensure User B does not receive that cached answer if it contains private information. As caching moves from simple text storage to complex vector-based retrieval, the intersection of efficiency and security will become a primary area of research.
In conclusion, inference caching is the bridge between AI as a research novelty and AI as a sustainable utility. By leveraging the technical foundations of KV caching, the structural advantages of prefix caching, and the high-level intelligence of semantic caching, organizations can build AI systems that are not only smarter but also faster and more economically viable. As the technology matures, these caching layers will likely become invisible, integrated so deeply into the fabric of the internet that the concept of "re-computing" a common query will seem as antiquated as re-loading an entire webpage for every single click.




{kind=link}