

Generative AI regurgitates training data copyright fair use – this seemingly simple phrase encapsulates a complex legal and ethical dilemma at the heart of artificial intelligence development. As AI models become increasingly sophisticated, their ability to generate text, images, and even music that closely resembles human-created works raises crucial questions about copyright infringement and the boundaries of fair use.
Imagine an AI model trained on a massive dataset of copyrighted music, generating a new song that sounds eerily familiar to a popular track. Is this plagiarism? Or is it a legitimate application of fair use, where the AI is borrowing elements to create something new and transformative?
These are the kinds of questions we need to grapple with as AI technology continues to evolve.
Generative AI and Copyright Law

The rise of generative AI has brought new challenges to the legal landscape of copyright law. Generative AI systems, trained on vast datasets of copyrighted material, can produce outputs that resemble existing works, raising questions about the ownership and protection of these outputs.
This article explores the interplay between generative AI and copyright law, examining the legal framework and its application to AI-generated content.
Copyright Law’s Scope and Protection
Copyright law is a complex legal framework that protects original works of authorship, including literary, dramatic, musical, and certain other intellectual works. The fundamental purpose of copyright law is to incentivize creativity by granting exclusive rights to authors over their original works.
These rights include the right to reproduce, distribute, display, perform, and create derivative works based on the copyrighted material. To be eligible for copyright protection, a work must meet certain criteria:
- Originality: The work must be independently created by the author and not simply a copy of another work.
- Fixation: The work must be expressed in a tangible medium of expression, such as a written document, a recording, or a digital file.
- Authorship: The work must be created by a human author, not by a machine or a natural process.
Training Data and Copyright Infringement
Generative AI models, trained on vast datasets of text, images, and other content, have the potential to infringe copyright if they are trained on copyrighted material without proper authorization. This potential for infringement arises from the way these models learn and generate new content, drawing heavily on the patterns and structures present in their training data.
Copyright Infringement Through Mimicry
The use of copyrighted material in training data can lead to generative AI models reproducing or mimicking copyrighted works. This happens because the model learns the underlying patterns and characteristics of the copyrighted content, including its style, language, and structure.
When prompted to generate new content, the model might inadvertently create outputs that are substantially similar to the copyrighted works it was trained on. For example, if a generative AI model is trained on a large dataset of novels written by a particular author, it might learn the author’s unique writing style, vocabulary, and plot structures.
As a result, when prompted to write a new story, the model might generate a story that closely resembles the author’s work, potentially leading to copyright infringement.
Legal Implications of Using Copyrighted Data Without Permission
Using copyrighted data without permission or authorization for training generative AI models raises several legal implications:
- Copyright Infringement:Using copyrighted material without permission for training purposes can be considered copyright infringement, particularly if the AI model’s outputs are substantially similar to the copyrighted works.
- Fair Use Doctrine:The fair use doctrine might provide some protection for using copyrighted material for training purposes. However, the application of fair use in this context is still evolving and uncertain, and courts might interpret it differently depending on the specific circumstances.
Investigate the pros of accepting flying car startup eyes takeoff following us eu certification in your business strategies.
- Licensing Agreements:Obtaining licenses from copyright holders is a crucial step to mitigate legal risks. Licensing agreements can specify the terms and conditions for using copyrighted material in training generative AI models.
The Role of Data Filtering and Anonymization
While obtaining licenses is the most straightforward way to ensure legal compliance, other techniques can help mitigate the risk of copyright infringement:
- Data Filtering:Filtering the training data to remove copyrighted content or exclude specific authors or works can help reduce the chances of the AI model mimicking copyrighted works.
- Data Anonymization:Anonymizing the training data can help obscure the source of the content, making it more difficult to identify specific copyrighted works used in the training process.
It is important to note that these techniques are not foolproof and might not completely eliminate the risk of copyright infringement. The legal landscape surrounding generative AI and copyright is rapidly evolving, and the best practices for using copyrighted data in training are still being defined.
Fair Use Doctrine and Generative AI
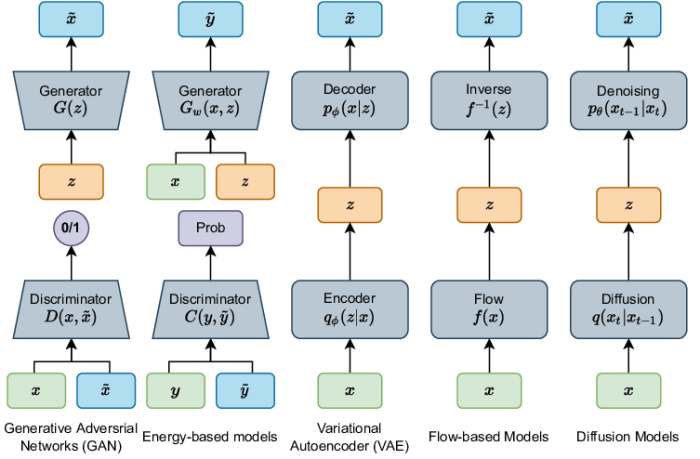
The fair use doctrine, a crucial component of US copyright law, allows for the limited use of copyrighted material without permission from the copyright holder. However, its application to generative AI models, which are trained on massive datasets that may include copyrighted works, presents unique challenges.
Factors Considered in Determining Fair Use
The fair use doctrine is based on a four-factor analysis, which considers the purpose and character of the use, the nature of the copyrighted work, the amount and substantiality of the portion used, and the effect of the use on the potential market for or value of the copyrighted work.
These factors are applied in a flexible and fact-specific manner, and no single factor is determinative.
Purpose and Character of the Use
The purpose and character of the use is the most important factor in the fair use analysis. Courts consider whether the use is transformative, meaning that it adds something new or different to the original work. Examples of transformative uses include:
- Parody
- Criticism
- Commentary
- News reporting
- Educational purposes
If the use is transformative, it is more likely to be considered fair use.
Nature of the Copyrighted Work
The nature of the copyrighted work is also considered. Courts are more likely to find fair use when the work is factual or non-fiction, rather than creative or fictional. This is because factual works are considered to be more readily available for public use.
Amount and Substantiality of the Portion Used
The amount and substantiality of the portion used is another important factor. The more of the original work that is used, the less likely it is to be considered fair use. However, even a small amount of the original work can be infringing if it is the heart of the work.
Effect of the Use on the Potential Market for or Value of the Copyrighted Work
The final factor is the effect of the use on the potential market for or value of the copyrighted work. If the use is likely to harm the market for the original work, it is less likely to be considered fair use.
Examples of Fair Use in Generative AI
The fair use doctrine can be applied to generative AI models in a variety of ways. For example, generative AI models could be used for:
- Educational purposes:A generative AI model could be used to create educational materials, such as summaries of copyrighted works, or to generate creative writing prompts based on existing literature.
- Research:A generative AI model could be used to analyze large datasets of copyrighted works, such as to identify trends in language or to create new forms of art.
- Commentary:A generative AI model could be used to create commentary on copyrighted works, such as by generating reviews or critiques.
However, it is important to note that the fair use doctrine is a complex legal issue, and there is no guarantee that any particular use of generative AI will be considered fair use.
Ethical Considerations of Generative AI and Copyright: Generative Ai Regurgitates Training Data Copyright Fair Use
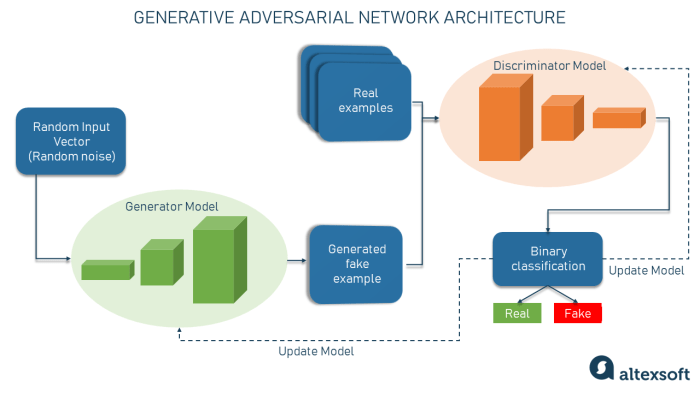
The rapid development of generative AI has raised significant ethical concerns regarding copyright. These models are trained on vast datasets that often include copyrighted material, leading to potential issues of infringement and plagiarism. This section delves into the ethical implications of using copyrighted material in generative AI training and explores strategies for mitigating these concerns.
Potential for Unintentional Copyright Infringement
Generative AI models can inadvertently reproduce copyrighted material during their training process. The models learn patterns and relationships from the training data, including copyrighted works. When generating new content, the models may output results that closely resemble or even directly copy elements from the original copyrighted works.
This poses a significant ethical challenge, as it raises questions about ownership, attribution, and the potential for unauthorized use of protected content.
Concerns About Originality and Plagiarism
The ability of AI models to generate content that closely resembles existing copyrighted works raises concerns about originality and plagiarism. When an AI model produces a piece of content that is too similar to a copyrighted work, it becomes difficult to determine whether the AI model is merely mimicking or truly creating something original.
This ambiguity can lead to accusations of plagiarism and raise questions about the authenticity and originality of AI-generated content.
Strategies for Mitigating Ethical Concerns, Generative ai regurgitates training data copyright fair use
Several strategies can be employed to mitigate ethical concerns associated with generative AI and copyright.
- Using Non-Copyrighted Training Data:One approach is to train AI models on datasets that exclude copyrighted material. This can involve using publicly available data, creative commons licensed content, or data specifically created for AI training. By limiting the exposure of the model to copyrighted works, the risk of unintentional infringement can be reduced.
- Implementing Safeguards to Prevent Copyright Infringement:Developers can implement safeguards within AI models to prevent copyright infringement. This can include techniques like watermarking, content filtering, and similarity detection algorithms. These safeguards can help identify and block the generation of content that infringes on existing copyrights.
- Promoting Transparency About the Sources of AI-Generated Content:Transparency is crucial for addressing ethical concerns. Developers should provide clear information about the sources of training data used for generative AI models. This transparency allows users to understand the potential for copyright infringement and make informed decisions about the use of AI-generated content.
Future Directions and Challenges
The intersection of generative AI and copyright law is a dynamic and evolving landscape. As AI technology advances, the legal framework surrounding copyright must adapt to address new challenges and ensure a balanced approach that fosters innovation while protecting creators’ rights.
This section explores key future directions and challenges, analyzing their current status, potential solutions, and their impact on the development and application of generative AI.
The Legal Framework Surrounding Copyright and AI
The legal framework surrounding copyright and AI is a complex and evolving area. Current laws were not designed with generative AI in mind, and there is no clear consensus on how they should be applied to AI-generated works.
- Issue:The legal status of AI-generated works.
- Current Status:There is no clear consensus on whether AI-generated works can be copyrighted. Some argue that AI is simply a tool and that the copyright should belong to the human creator who instructed the AI. Others argue that AI-generated works are original and should be eligible for copyright protection.
- Potential Solutions:One potential solution is to amend copyright law to explicitly address AI-generated works. This could involve creating a new category of copyright for AI-generated works, or establishing clear guidelines for determining authorship and ownership in AI-generated works. Another approach is to develop a framework for licensing AI-generated works, allowing creators to control how their works are used and shared.
- Impact on Generative AI:Clarity on the legal status of AI-generated works is crucial for the future of generative AI. A clear legal framework will provide certainty for creators, developers, and users, encouraging investment and innovation in this field.
The Role of Fair Use in Generative AI
The fair use doctrine allows for limited use of copyrighted works without permission for purposes such as criticism, commentary, news reporting, teaching, scholarship, and research.
- Issue:The application of fair use to generative AI models trained on copyrighted data.
- Current Status:The application of fair use to generative AI models trained on copyrighted data is a subject of ongoing debate. Some argue that the use of copyrighted data for training AI models is a transformative use that falls under fair use, while others argue that it is a copyright infringement.
- Potential Solutions:One potential solution is to establish clear guidelines for determining when the use of copyrighted data for AI training qualifies as fair use. These guidelines could consider factors such as the purpose and character of the use, the nature of the copyrighted work, the amount and substantiality of the portion used, and the effect of the use on the potential market for the copyrighted work.
- Impact on Generative AI:A clear understanding of fair use in the context of generative AI is essential for fostering innovation. It will allow developers to confidently train AI models on large datasets without fear of copyright infringement, while ensuring that the rights of copyright holders are protected.
Ethical Considerations and Responsible AI Development
The development and use of generative AI raise significant ethical considerations.
- Issue:The potential for generative AI to be used to create and disseminate harmful content, such as deepfakes or misinformation.
- Current Status:There is growing concern about the potential for generative AI to be used for malicious purposes. Deepfakes, which are synthetic videos that convincingly portray real people saying or doing things they never did, have already been used to spread misinformation and harm individuals’ reputations.
- Potential Solutions:Several solutions are being explored to mitigate the ethical risks associated with generative AI. These include developing tools for detecting and identifying AI-generated content, promoting responsible AI development practices, and establishing ethical guidelines for the use of generative AI.
- Impact on Generative AI:Addressing ethical concerns is crucial for ensuring the responsible development and use of generative AI. By developing safeguards and promoting ethical practices, we can harness the power of generative AI for good while mitigating its potential harms.
The Impact of Copyright Law on the Future of Generative AI
Copyright law will play a significant role in shaping the future of generative AI.
- Issue:The impact of copyright law on the development and application of generative AI.
- Current Status:The current legal framework surrounding copyright and AI is uncertain, creating challenges for developers and users. This uncertainty can stifle innovation and limit the potential of generative AI.
- Potential Solutions:A clear and balanced legal framework that addresses the unique challenges posed by generative AI is essential. This framework should strike a balance between protecting creators’ rights and fostering innovation.
- Impact on Generative AI:A clear legal framework will provide certainty and stability for the generative AI ecosystem, encouraging investment, development, and adoption. It will also help to ensure that generative AI is used responsibly and ethically.
{kind=link}